Normalisatie en Standaardisatie
Voorbeeld
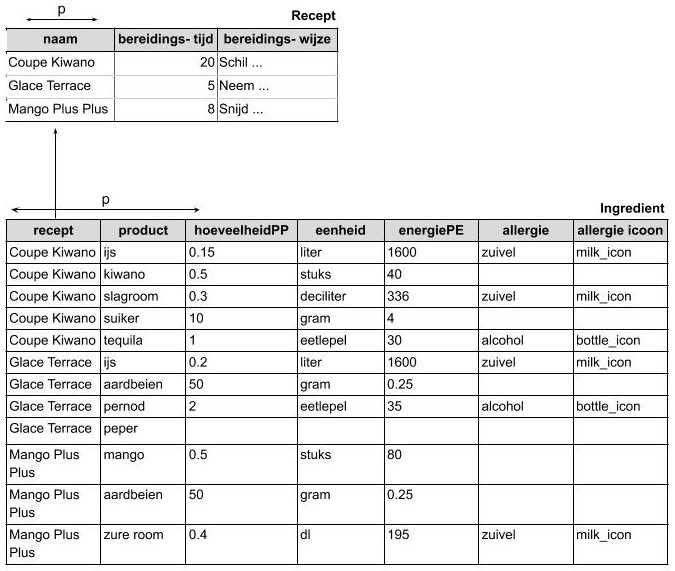
Dit deel vertrekt vanuit een database die nog veel redundantie, herhalende groepen en niet-gestandaardiseerde waardes bevat.
| naam | energiePP | bereidingstijd | bereidingswijze | ingrediënten | |||
|---|---|---|---|---|---|---|---|
| product | hoeveelheidPP | eenheid | energiePE | ||||
| Coupe Kiwano | 431 | 20 | Schil | ijs | 0.15 | liter | 1600 |
| kiwano | 0.5 | stuks | 40 | ||||
| slagroom | 0.3 | deciliter | 336 | ||||
| suiker | 10 | gram | 4 | ||||
| tequila | 1 | eetlepel | 30 | ||||
| Glace Terrace | 403 | 5 | Neem | ijs | 0.2 | liter | 1600 |
| aardbeien | 50 | gram | 0.25 | ||||
| pernod | 2 | eetlepel | 35 | ||||
| peper | |||||||
| Mango Plus Plus | 131 | 8 | Snij | mango | 0.5 | stuks | 80 |
| aardbeien | 50 | gram | 0.25 | ||||
| zure room | 0.4 | deciliter | 195 | ||||
Een verbeterde tabelstructuur
Wanneer een tabel herhalende groepen en/of redundantie bevat, is dit omdat die tabel meerdere ‘soorten dingen’ bevat (in de voorbeelden hierboven bevat de tabel zowel ‘recepten’ als ‘ingrediënten’).
Zo één ‘ding’ wordt een entiteit genoemd. Eén ‘soort ding’ wordt dan een entiteit type. Zo is bijvoorbeeld ‘Coupe Kiwano’ een entiteit en het entiteittype ervan ‘recept’. ‘ijs’ is ook een entiteit, het entiteittype ervan is ‘ingredient’.
Het verwijderen of beperken van herhalende groepen en redundantie, door tabellen van een grotere tabel af te splitsen, heet normaliseren.
Het verwijderen of beperken van niet-gestandaardiseerde gegevens, door deze in een aparte tabel te plaatsen, heet standaardisatie.
Meerdere tabellen
In de oorspronkelijke tabel, met een volledig recept per rij, waren ingrediënten ondergeschikt aan gerechten. Het was onmogelijk om een ingredient aan de databank toe te voegen, zonder een bijbehorend gerecht. Er vindt dus een ongelijkwaardige behandeling plaats van verschillende data.
Het zou dus beter zijn om een aparte tabel te hebben met producten die je kan gebruiken in een recept. Zo kan op voorhand al een product aan de database worden toegevoegd met alle nodige informatie.
Dit is een belangrijk principe in database-ontwerp: Elk entiteittype krijgt zijn eigen tabel.
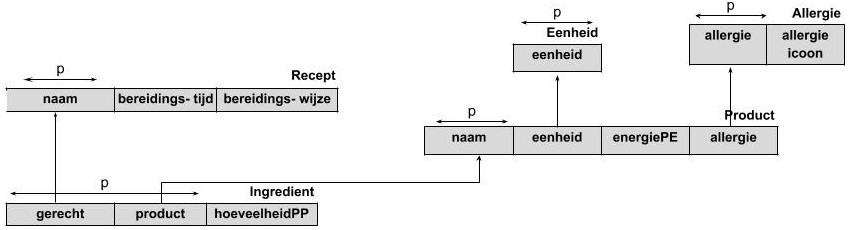
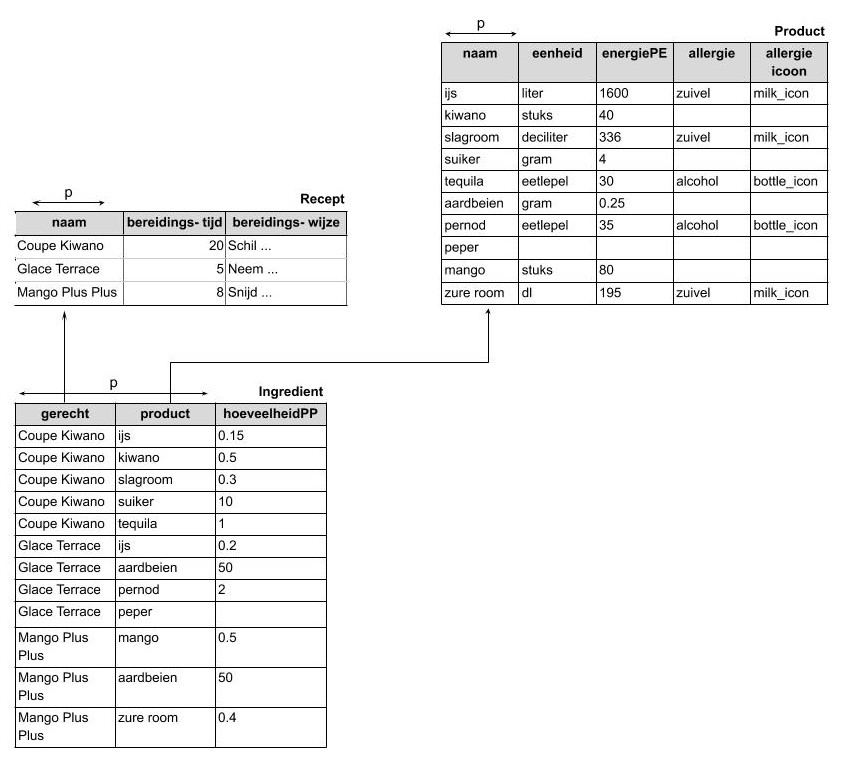
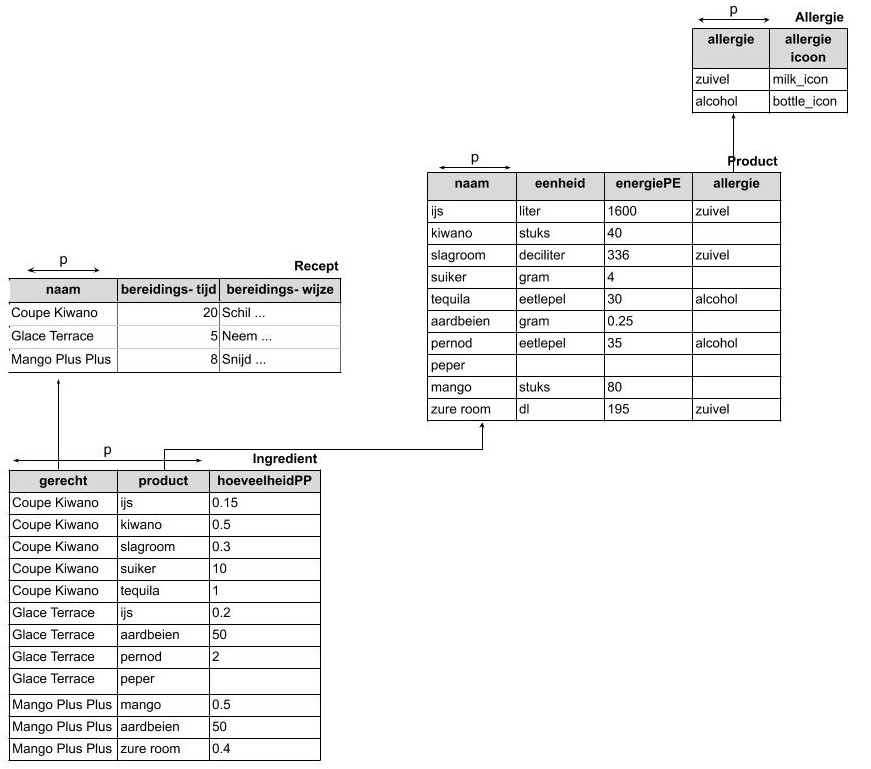
In het volgende voorbeeld is de databank voor Désiré’s Dessertenboek verdeeld in verschillende tabellen die onderling verbonden zijn.
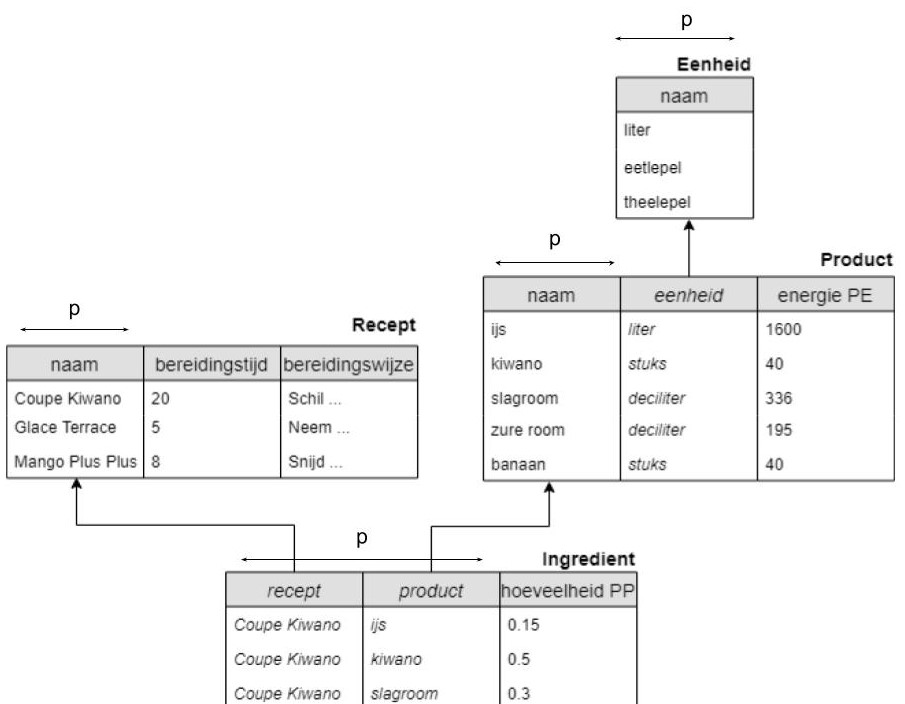
De voorbeeldpopulatie is wat kleiner gemaakt om de afbeelding leesbaarder te maken
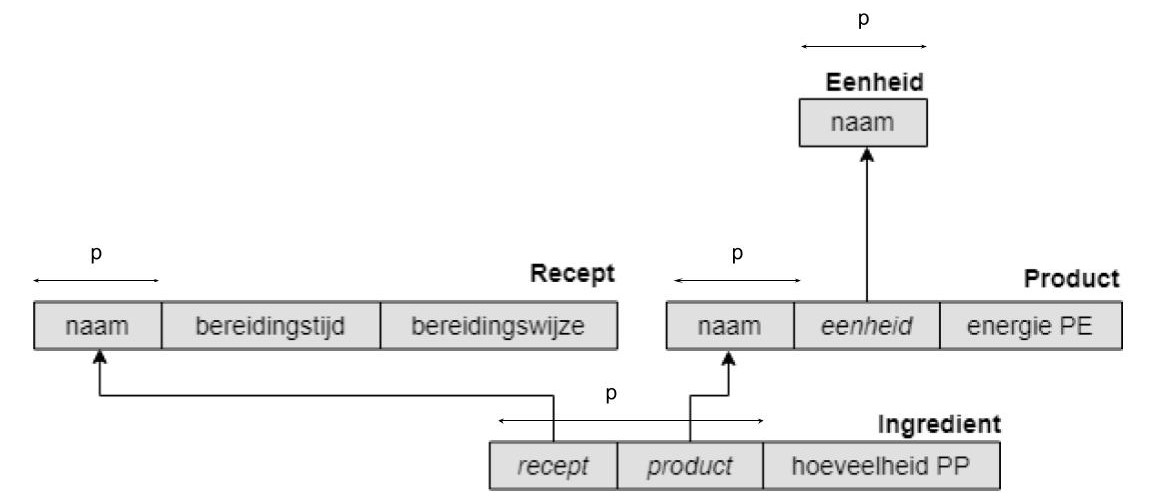
Het strokendiagram
Er zijn nu vier tabellen gemaakt in plaats van één:
- Recept: Hierin bevindt zich de informatie die alléén met recepten te maken heeft.
- Product: Hierin bevindt zich de informatie die alléén met producten te maken heeft.
- Ingrediënt: Hier vertellen we welk product (uit de tabel ‘Product’) gebruikt wordt in welk recept (uit de tabel ‘Recept’).
- Eenheid: Hierin zijn alle mogelijke eenheden verzameld die gebruikt kunnen worden door een product.
In deze structuur zijn alle herhalende groepen verwijderd. Er is geen enkele samengestelde kolom meer te vinden.
In deze structuur is alle redundantie zoveel mogelijk beperkt omdat ‘Coupe Kiwano’ maar éénmaal voorkomt in de database (nl. In de tabel ‘Recept’), behalve als refererende sleutel.
Om dezelfde reden zijn ook alle niet-gestandaardiseerde waarden verwijderd: zo komt ‘eetlepel’ maar éénmaal voor in de databank (in de tabel ‘Eenheid’), behalve als refererende sleutel.
Deze structuur heet een volledig genormaliseerde structuur.
Normalisatie
Normalisatie is het proces om in een database herhalende groepen en redundantie te elimineren. Dit proces bestaat uit verschillende stappen die één voor één worden afgewerkt.
Elke stap in dat proces heet een normaalvorm. Door de regels van elke normaalvorm toe te passen, is een databank weer een stapje dichter bij volledige normalisatie.
Er bestaan een tiental verschillende normaalvormen. Afhankelijk van de databank en het vooropgestelde doel gebruik je verschillende normaalvormen tijdens de normalisatie.
Bijna elke normalisatie begint echter met dezelfde drie normaalvormen:
- Normaalvorm 1
- Normaalvorm 2
- Normaalvorm 3
Veel (kleinere) databanken hebben genoeg aan deze drie normaalvormen om tot een volledig genormaliseerde structuur te komen.
Normaalvorm1 (NF1)
De regels voor de eerste normaalvorm zijn:
- De tabel heeft een primaire sleutel.
- Elke kolom bevat atomaire waarden en er zijn geen herhalende groepen van de kolommen.
Normalisatie is het proces om in een database herhalende groepen en redundantie te elimineren. De eerste normaalvorm draait om het elimineren van herhalende groepen. In de onderstaande tabel zijn er meerdere ingrediënten per recept. Dit is dus een herhalende groep.
| naam | energiePP | bereidingstijd | bereidingswijze | ingrediënten | |||
|---|---|---|---|---|---|---|---|
| product | hoeveelheidPP | eenheid | energiePE | ||||
| Coupe Kiwano | 431 | 20 | Schil | ijs | 0.15 | liter | 1600 |
| kiwano | 0.5 | stuks | 40 | ||||
| slagroom | 0.3 | deciliter | 336 | ||||
| suiker | 10 | gram | 4 | ||||
| tequila | 1 | eetlepel | 30 | ||||
| Glace Terrace | 403 | 5 | Neem | ijs | 0.2 | liter | 1600 |
| aardbeien | 50 | gram | 0.25 | ||||
| pernod | 2 | eetlepel | 35 | ||||
| peper | |||||||
| Mango Plus Plus | 131 | 8 | Snij | mango | 0.5 | stuks | 80 |
| aardbeien | 50 | gram | 0.25 | ||||
| zure room | 0.4 | deciliter | 195 | ||||
Deze tabel in normaalvorm 1 zetten gebeurt in 2 stappen:
- Maak een nieuwe tabel aan genaamd “Ingredient” en plaats daar alle herhalende groepen in.
- Verwijder de herhalende groepen uit de oorspronkelijke tabel.
Het strokendiagram ziet er dan als volgt uit:
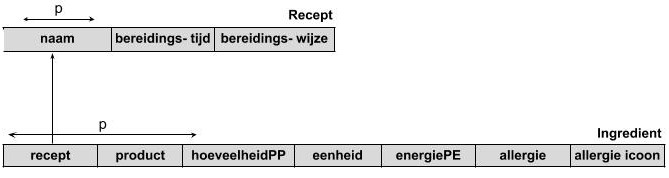
In de nieuwe tabel valt er een aantal zaken op:
- Een refererende sleutel wordt toegevoegd die verwijst naar de oorspronkelijke tabel. Dit is nodig, omdat anders deze informatie verloren geraakt: welk gerecht gebruikte welk ingrediënt?
- Er wordt een primaire sleutel gekozen en aangeduid. Dit is immers een nieuwe tabel in de databank, en elke tabel moet een primaire sleutel hebben!
Normaalvorm2 (NF2)
De regels voor de tweede normaalvorm zijn:
- De tabel is in de eerste normaalvorm (NF1).
- Alle velden die geen kandidaat sleutel zijn, zijn functioneel afhankelijk van de volledige primaire sleutel van die tabel.
De primaire sleutel is een waarde die een record uniek maakt.
Functioneel afhankelijk wilt zeggen dat de waarde in één kolom bepaalt welke waarde in een andere kolom staat. We zeggen: bereidingstijd is functioneel afhankelijk van naam. Dit betekent niets anders dan dat bij één waarde van naam één waarde van bereidingstijd hoort.
Dit wordt in het strokendiagram zo aangeduid:
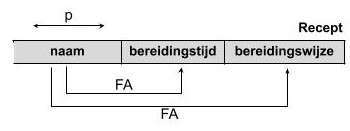
Partiële afhankelijkheid wilt zeggen dat de primaire sleutel uit meerdere kolommen bestaat, maar dat er maar één kolom uit de primaire sleutel de waarde bepaalt van een andere kolom.
Bijvoorbeeld:
In de tabel Ingrediënt is de kolom eenheid functioneel afhankelijk van de kolom product, maar niet van de kolom gerecht. In dit geval is er dus sprake van partiële afhankelijkheid.
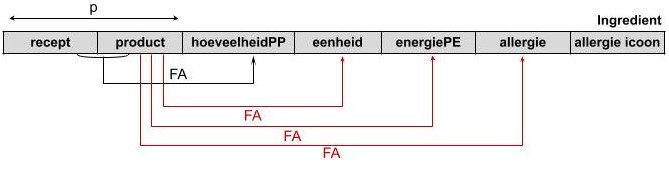
De tweede normaalvorm houdt in dat partiële afhankelijkheden worden geëlimineerd.
Deze tabel in normaalvorm 2 zetten gebeurt in 2 stappen:
- Maak een nieuwe tabel aan genaamd “Product” en plaats daar alle partiële afhankelijkheden in.
- Verwijder de partiële afhankelijkheden uit de oorspronkelijke tabel.
Het strokendiagram ziet er dan als volgt uit:
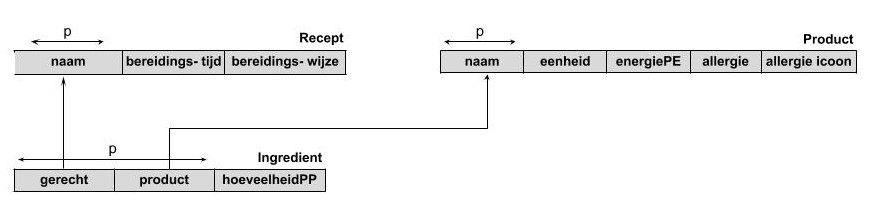
Normaalvorm3 (NF3)
De regels voor de derde normaalvorm zijn:
- De tabel is in de tweede normaalvorm (NF2).
- Alle velden die geen kandidaat sleutel zijn, zijn functioneel onafhankelijk van alle andere velden die geen kandidaat sleutel zijn.
De databank bevat nog steeds een functionele afhankelijkheid die redundantie kan veroorzaken: een niet-sleutelkolom die afhankelijk is van een andere niet-sleutelkolom.

De derde normaalvorm houdt in dit soort afhankelijkheden worden geëlimineerd.
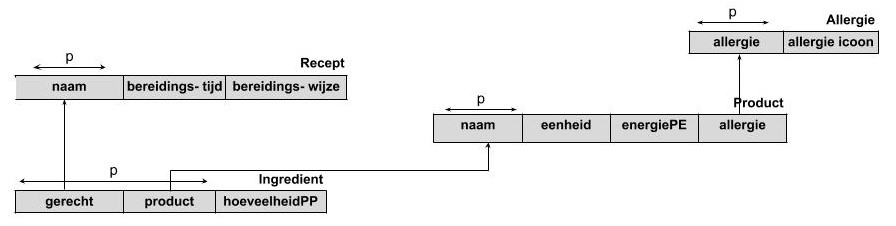
Deze tabel in normaalvorm 3 zetten gebeurt in 2 stappen:
- Maak een nieuwe tabel aan genaamd “Eenheid” en plaats daar alle afhankelijkheden in.
- Verwijder de afhankelijkheden uit de oorspronkelijke tabel.
Het strokendiagram ziet er dan als volgt uit:
Standaardisatie
Nauw verbonden met normaliseren is het standaardiseren van bepaalde gegevens.
In het voorbeeld zijn de namen van eenheden (bv. ‘deciliter’, ‘dl’, ‘kilogram’, ‘kg’, …) niet gestandaardiseerd. Erger nog, die standaardisatie is zelfs niet verplicht! Niets verbiedt de gebruiker om ‘slagroom’ te meten in ‘deciliter’ en zure room in ‘dl’, hoewel dat dezelfde eenheid is. Een relationele structuur biedt een eenvoudige manier om standaardisatie van gegevens af te dwingen:
- Maak een nieuwe tabel aan genaamd “Eenheid” en plaats daar alle unieke (gestandaardiseerde) waarden in.
- Voeg een referentie toe in de oorspronkelijke tabel.
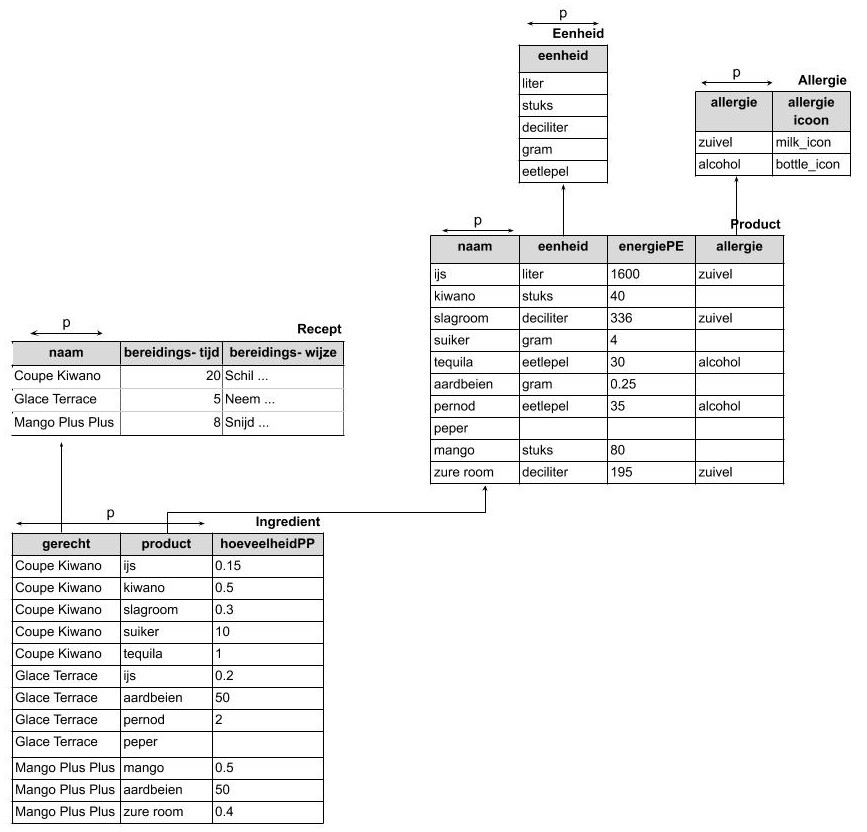
Het strokendiagram ziet er dan als volgt uit: